ヴィクトリア朝時代の資料のみで学習した言語モデル「Mr. Chatterbox」 - GIGAZINE
https://gigazine.net/news/20260401-mr-chatterbox/The evidence pack includes HTML, screenshots, summaries, and metadata. It can be downloaded on Pro.
ヴィクトリア朝時代の資料のみで学習した言語モデル「Mr. Chatterbox」 - GIGAZINE
Open the archived HTML with saved-time metadata attached.
This HTML has CSS and images embedded, so it can still be opened even if the original page disappears.
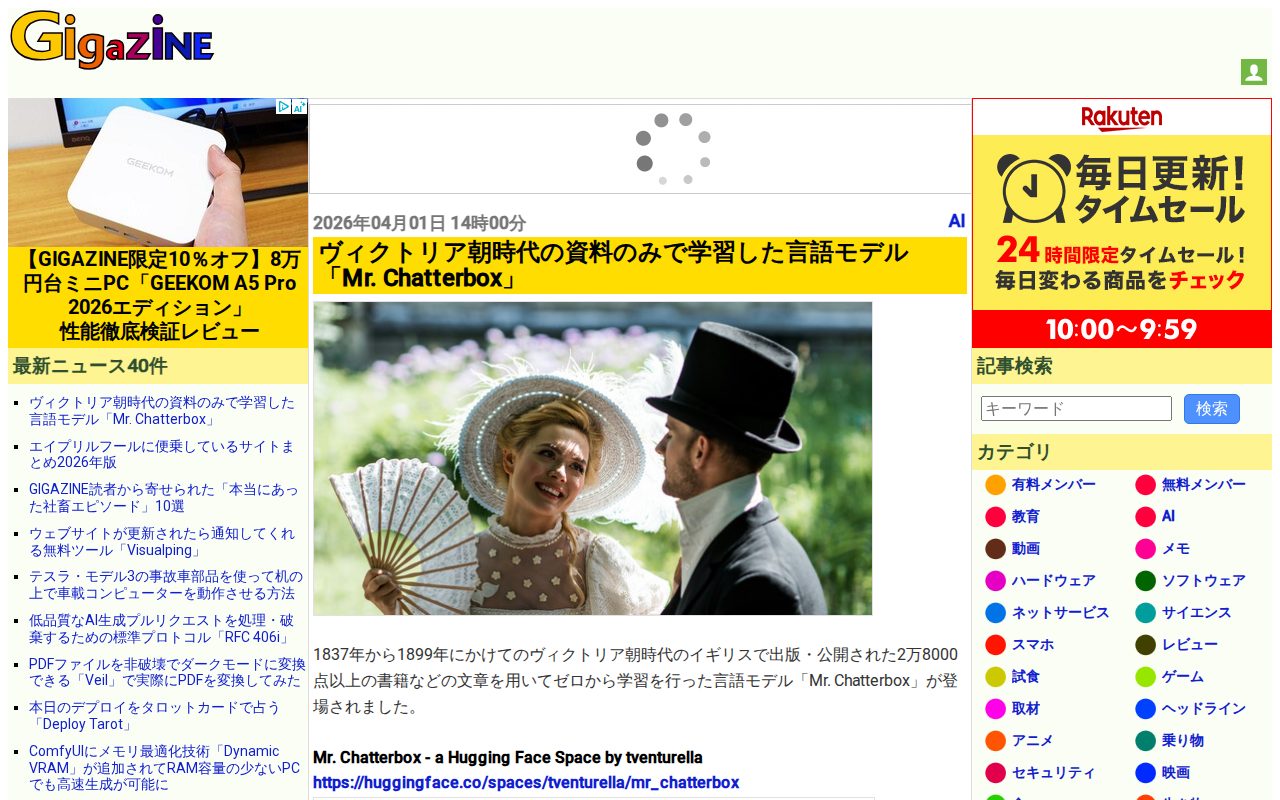
This page introduces "Mr. Chatterbox," a language model trained exclusively on Victorian-era texts from 1837-1899. Trip Venturella developed it using 28,035 documents from the British Library's public domain dataset, focusing solely on Victorian-era publications. The model has approximately 340 million parameters, similar to GPT-2-Medium, and specializes in Victorian life, literature, science, and philosophy. Since it's in beta, responses are unstable and limited. The article notes that achieving conversational quality with only public domain data requires significantly more training material.