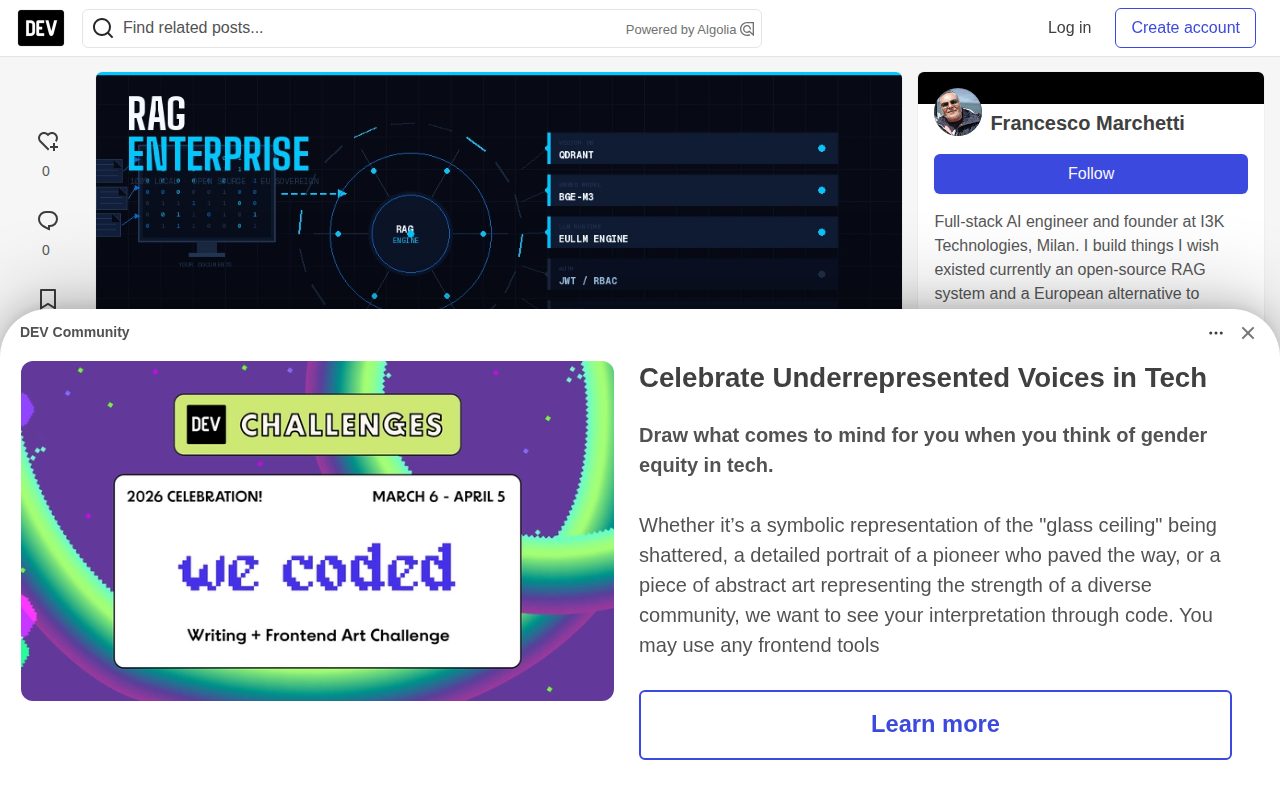
Archive ready
I built a self-hosted RAG system that actually works — here's how to run it in one command - DEV Community
https://dev.to/primoco/i-built-a-self-hosted-rag-system-that-actually-works-heres-how-to-run-it-in-one-command-38p2April 1, 2026 at 08:35 PM JST•The archive page, viewer, and downloads use this saved version.
April 1, 2026 at 08:35 PM JST·dev.to
Bundle the HTML, screenshot, summaries, and metadata into one ZIP file. Pro saves automatically start preparing the external RFC 3161 timestamp, and only unfinished records need one more preparation step before download.